서론
개발자들이 흔히 저지르는 실수 중 하나는 요구사항을 듣고 이를 곧바로 비즈니스 로직이나 쿼리로 구현하는 것입니다. 이게 왜 문제가 될까요?
아래 이미지는 팀의 백엔드 개발자 채널 내용 중 일부입니다. 주목할 부분은 빨간색으로 표시된 요청사항입니다.
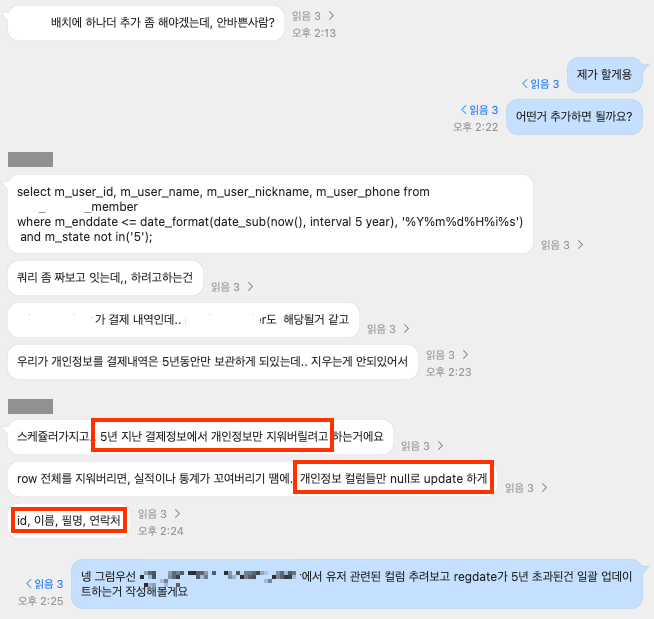
요청사항:
- 5년이 지난 결제 정보를 찾아, 개인정보 관련 특정 컬럼(id, 이름, 필명, 연락처)만 null로 업데이트하기.
요청사항만 보고 그대로 Spring Data JPA로 구현한다면, 보존 기간이 지난 데이터를 findAll()로 조회하고, 데이터가 많다면 청크 단위로 나눠서 saveAll()로 저장하면 된다고 생각할 수 있습니다. 하지만 이렇게 접근할 경우 큰 문제가 발생합니다.
Spring Data JPA의 saveAll은 개별 update 쿼리를 실행하는데, 특히 엔티티에 연관 관계(@OneToMany 등)가 설정된 경우에는 N+1 문제가 발생할 수 있습니다. 초기에는 데이터가 적어서 문제를 느끼지 못할 수 있지만, 데이터가 수만, 수십만, 혹은 수백만 건으로 증가하면 쿼리 실행 시간이 급격히 늘어납니다.
따라서, 요구사항을 그대로 구현하기보다는, 이 요청이 무엇을 해결하고자 하는지 깊이 있게 고민해 볼 필요가 있습니다.
1. JPA FindAll() saveAll() 사용의 문제점
아래는 예시 코드의 일부입니다.
@Transactional
public void deleteUserArchive() {
//보존기간 만료된 데이터 추출
List<User> users = userRepository.findAllByArchiveLimitDatetimeLessThan(DateUtils.currentDate(-5));
users.forEach(user -> {
//edu_member 계정 개인정보 삭제
log.info("삭제될 분리보관된 테이블 유저 : [{}]",user.getUserId());
List<Ticket> ticket = ticketRepository.findByUserId(user.getUserId());
log.info("개인정보가 삭제될 유저인원 : [{}]",ticket.size());
ticket.forEach(Ticket::deleteInfo);
eduMemberRepository.saveAll(ticket);
});
//보존기간이 만료된 분리보관된 데이터 제거
userRepository.deleteAllInBatch(users);
}JPA는 매우 강력한 ORM 도구이지만, 잘못 사용하면 서비스의 성능 저하를 일으킬 수 있습니다. 위 코드에서 deleteAllInBatch는 deleteAll과 달리 select 쿼리 없이 오로지 delete 쿼리만 실행하여 성능 면에서 더 유리합니다.
deleteAll()와 deleteAllInBatch() 비교
- deleteAll(): 각 엔티티에 대해 개별 삭제 처리를 진행하기 때문에, 엔티티가 많을 경우 성능 저하가 발생합니다. 연관된 엔티티의 조회 쿼리도 함께 실행될 수 있습니다.
- deleteAllInBatch(): select 쿼리를 수행하지 않고 단일 delete 쿼리만 실행해 성능이 훨씬 빠릅니다.
하지만 saveAll, findAll과 마찬가지로 deleteAllInBatch()도 연관 관계가 설정된 엔티티가 포함되어 있으면 조인 쿼리가 추가적으로 실행될 수 있습니다.
결론적으로, 위 로직에서 User 엔티티에 연관관계가 설정되어 있다면 전체 행이 100건인 경우, findByUserId 메서드는 사용자당 Ticket 데이터를 조회하기 때문에 100번 실행될 수 있습니다. 여기에 saveAll 호출이 연관된 엔티티마다 개별 쿼리로 실행된다면, 총 100건의 saveAll 쿼리가 추가로 실행될 수 있습니다. 따라서, 연관 관계가 있는 경우 N+1 문제가 발생할 가능성이 높아 성능 저하를 초래할 수 있습니다.
JPA를 사용할 때는 이러한 연관 관계와 쿼리 최적화 문제를 반드시 고려해야 합니다.
2. 접근 방식의 전환
대량 데이터 업데이트: 5년이 지난 결제 정보를 일괄 update하기 위해서는 JPA의 @Modifying과 @Query를 사용해 단일 SQL 쿼리로 한 번에 처리하는 것이 바람직합니다.
@Modifying
@Query("UPDATE Payment p SET p.userName = null, p.userId = null WHERE p.paymentDate < :date")
int nullifyUserInfoOlderThan(@Param("date") LocalDate date);대량 삭제 시 성능 최적화: 대량 데이터 삭제는 deleteAllInBatch를 활용하되, 필요한 경우 JPA가 아닌 네이티브 SQL 쿼리를 직접 사용하는 것도 좋은 방법입니다.
결론
요청사항을 그대로 구현하기보다는, 성능과 확장성에 문제가 없는지 고민하고 최적화된 방법을 선택해야 합니다. 특히 대용량 데이터를 다룰 때는 JPA의 편리함만을 믿고 처리하기보다는, 구체적인 쿼리 동작 방식을 이해하고 성능에 최적화된 접근 방식을 선택하는 것이 필요합니다.
'Framework > Spring Boot' 카테고리의 다른 글
| Spring Boot 기반 다수의 프로젝트를 하나의 Multi Module 프로젝트로 통합하기 (3) - 인증과 인가는 Gateway로, 토큰 발급은 Auth Api로 (2) | 2024.11.07 |
|---|---|
| [Query Tuning] Spring Batch 삭제 로직 성능 최적화 (2) | 2024.11.05 |
| Spring Boot 기반 다수의 프로젝트를 하나의 Multi Module 프로젝트로 통합하기 (2) - 인증과 인가를 담당하는 Auth Api (1) | 2024.11.01 |
| Spring Boot 기반 다수의 프로젝트를 하나의 Multi Module 프로젝트로 통합하기 (1) - 프로젝트를 시작하며 (3) | 2024.10.30 |
| Redis를 활용한 조회수 시스템 최적화와 동시성 이슈 해결 (1) | 2024.10.18 |

댓글