서론
게시글을 제공하는 모든 서비스에서는 게시글의 조회수를 다양한 방법으로 제공하고 있습니다. 저희 회사에서도 게시글의 조회수를 집계하기 위해 여러 방식을 사용해 왔습니다. 기존에는 게시글 상세 조회 시마다 접속 정보(게시글, 접속 장치, 접속 시간)를 RDB에 로그 형태로 단순 삽입하고, 일정 시간마다 배치 작업을 통해 실제 조회수 RDB를 업데이트하는 방식이었습니다.
하지만 이 방식은 시간이 지남에 따라 심각한 문제점을 드러냈습니다. 게시글의 수가 하루에도 몇십에서 몇백 개씩 증가하면서, 상세 조회마다 RDB에 Insert되는 횟수가 기하급수적으로 늘어났습니다. 이는 데이터베이스에 부하를 주고 성능 저하를 유발했습니다.
이를 해결하기 위해 조회수 데이터를 Redis에 저장하고, 배치 작업을 통해 RDB를 업데이트하는 방식으로 변경했습니다. 하지만 Redis를 도입하면서 새로운 동시성 이슈가 발생했고, 이를 해결하기 위해 여러 방법을 모색했습니다. 이번 포스팅에서는 Redis를 활용한 조회수 시스템 최적화 과정과 그 과정에서 마주친 동시성 이슈 및 해결 방법에 대해 다뤄보겠습니다.
1. 상세보기마다 조회수 RDB Insert시 문제점
문제점 설명
- 데이터베이스 부하 증가: 게시글 상세 조회 시마다 RDB에 Insert 작업을 수행하면, 트래픽이 많을 때 데이터베이스에 과부하가 걸릴 수 있습니다.
- 성능 저하: Insert 작업은 비교적 비용이 큰 연산이며, 특히 대량의 데이터가 쌓일 경우 쿼리 처리 속도가 느려질 수 있습니다.
- 스케일링의 어려움: 서비스가 성장함에 따라 게시글과 사용자 수가 증가하면, RDB에 대한 의존성이 병목현상을 유발할 수 있습니다.
예시
기존 시스템에서는 다음과 같은 방식으로 조회수를 처리했습니다.
-- 게시글 상세 조회 시마다 조회 기록 삽입
INSERT INTO article_view_logs (article_id, device_type, view_time)
VALUES (:articleId, :deviceType, NOW());
그리고 배치 작업을 통해 일정 시간마다 실제 조회수를 집계하여 업데이트했습니다.
-- 배치 작업에서 조회수 집계 및 업데이트
UPDATE articles a
JOIN (
SELECT article_id, COUNT(*) AS view_count
FROM article_view_logs
WHERE view_time BETWEEN :startTime AND :endTime
GROUP BY article_id
) v ON a.id = v.article_id
SET a.view_count = a.view_count + v.view_count;
이러한 방식은 초기에는 문제가 없었지만, 게시글과 사용자 수가 증가하면서 데이터베이스에 부담이 가중되었습니다.
2. Spring Data Redis의 활용과 그 문제점
Redis를 활용한 조회수 처리
Redis는 인메모리 데이터 저장소로서 높은 성능과 빠른 응답 속도를 제공합니다. 이에 따라 조회수 데이터를 Redis에 저장하고, 일정 시간마다 RDB로 옮기는 방식을 고려했습니다.
@Service
public class ArticleHitService {
@Autowired
private ArticleHitRepository articleHitRepository;
public void incrementHitCount(String articleId) {
// Redis에 조회수 증가
ArticleHit articleHit = articleHitRepository.findById(articleId)
.orElse(new ArticleHit(articleId, 0));
articleHit.increment();
articleHitRepository.save(articleHit);
}
}동시성 이슈 발생
하지만 findById()와 save() 사이에 다른 스레드에서 조회수가 증가하면 데이터가 덮어써지는 동시성 문제가 발생했습니다.
문제 상황
- 스레드 A가 findById()로 조회하여 조회수 10을 가져옴.
- 스레드 B가 findById()로 동일한 조회수 10을 가져옴.
- 스레드 A가 조회수 1 증가하여 11로 저장.
- 스레드 B가 조회수 1 증가하여 11로 저장.
- 실제로는 조회수가 2 증가해야 하지만, 최종 조회수는 11이 됨.
3. RedisTemplate을 활용한 increment 구현으로 동시성 이슈 해결
Redis의 원자적 연산을 활용
Redis는 원자적 증가 연산을 지원합니다. 이를 활용하면 동시성 문제를 해결할 수 있습니다. RedisTemplate의 increment() 메서드를 사용하여 조회수를 증가시킵니다.
@Service
public class ArticleHitService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
private static final String KEY_PREFIX = "article-hit";
public int incrementPcHitCount(String articleId, Integer hits) {
String key = KEY_PREFIX + ":" + articleId;
Long updatedValue = redisTemplate.opsForHash().increment(key, "hitCount", hits);
redisTemplate.opsForSet().add(KEY_PREFIX, articleId);
return updatedValue.intValue();
}
public int incrementMobileHitCount(String articleId, Integer hits) {
String key = KEY_PREFIX + ":" + articleId;
Long updatedValue = redisTemplate.opsForHash().increment(key, "mobileHitCount", hits);
redisTemplate.opsForSet().add(KEY_PREFIX, articleId);
return updatedValue.intValue();
}
}사용해야 하는 이유
- 원자성 보장: Redis의 HINCRBY 명령어는 원자적으로 실행되므로 동시성 문제가 발생하지 않습니다.
- 성능 향상: 별도의 조회 없이 바로 증가시키므로 성능이 향상됩니다.
- 코드 간결화: findById()와 save()를 사용할 필요가 없어 코드가 간결해집니다.
4. RDB Insert시 Redis 데이터 Select 및 Delete에서 동시성 이슈 발견
문제 상황
배치 작업에서 Redis에 저장된 조회수 데이터를 가져와 RDB에 반영하고, Redis의 해당 데이터를 삭제하는 과정에서 동시성 문제가 발생했습니다.
@Service
public class ArticleHitStorageService {
@Autowired
private ArticleHitRepository articleHitRepository;
@Autowired
private ArticleHitStorageRepository articleHitStorageRepository;
public void updateHitStorage() {
// Redis에서 모든 조회수 데이터 가져오기
List<ArticleHit> articleHits = articleHitRepository.findAll();
// Redis에서 데이터 삭제
articleHitRepository.deleteAll(articleHits);
// RDB에 조회수 업데이트
for (ArticleHit articleHit : articleHits) {
articleHitStorageRepository.incrementHitCount(
articleHit.getArticleId(),
articleHit.getHitCount()
);
}
}
}동시성 문제 발생
findAll()과 deleteAll() 사이에 다른 스레드가 조회수를 증가시키면, 해당 데이터는 배치 작업에서 처리되지 않고 Redis에 남게 됩니다. 이는 데이터 불일치로 이어질 수 있습니다. 실제로 테스트 결과 예상치랑 몇개의 근사한 차이로 값이 일치하지 않는 것을 확인했습니다.
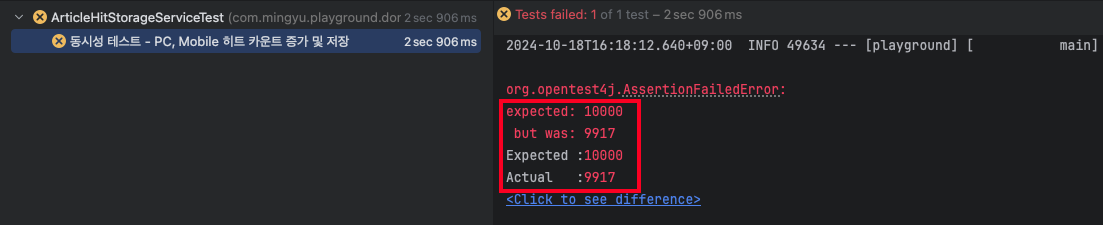
5. Lua Script를 활용한 동시성 이슈 해결
Lua Script를 사용한 원자적 연산
Redis에서 Lua 스크립트를 사용하면 여러 명령을 원자적으로 실행할 수 있습니다. 이를 활용하여 조회수 데이터를 가져오고 삭제하는 작업을 원자적으로 수행합니다.
-- Lua 스크립트 정의
local keys = redis.call('SMEMBERS', KEYS[1])
local result = {}
for _, key in ipairs(keys) do
local data = redis.call('HGETALL', key)
table.insert(result, key)
for i, v in ipairs(data) do
table.insert(result, v)
end
redis.call('DEL', key)
end
redis.call('DEL', KEYS[1])
return resultpublic List<ArticleHit> getAndDeleteAllArticleHits() {
String script = "..." // 위 Lua 스크립트 내용
RedisScript<List> redisScript = RedisScript.of(script, List.class);
List<Object> result = redisTemplate.execute(redisScript, Collections.singletonList("article-hit"));
// 결과 파싱 및 ArticleHit 객체 생성
List<ArticleHit> articleHits = parseResult(result);
return articleHits;
}좋은 점
- 원자성 보장: Lua 스크립트 내의 모든 명령이 단일 명령으로 실행되므로 동시성 문제가 발생하지 않습니다.
- 데이터 일관성 유지: 조회와 삭제가 동시에 이루어져 데이터의 일관성을 보장합니다.
- 성능 향상: 네트워크 오버헤드를 줄이고 성능을 최적화합니다.
주의 사항
- 스크립트 유지보수: Lua 스크립트는 복잡할 수 있으므로 주석과 문서를 통해 관리해야 합니다.
- 에러 처리: 스크립트 실행 중 발생할 수 있는 예외를 적절히 처리해야 합니다.
실제로 Lua 스크립트를 활용한 getAndDeleteAllArticleHits()를 사용했을 때 원하던 값을 명확히 얻을 수 있었습니다.
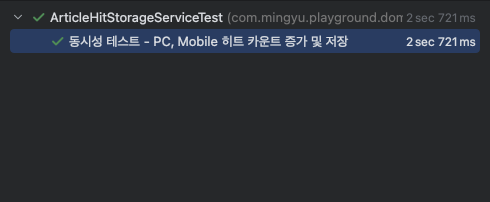
6. 테스트 케이스 작성 및 테스트 확인
Pc, Mobile 조회수 증가 동시성 테스트
테스트 케이스를 작성하는 것은 이번 프로젝트에서 가장 어려운 부분 중 하나였습니다. 단위 테스트와 기능 테스트로 진행하려 했지만, 실제로 Redis와 RDB에 데이터가 예상대로 쌓이는지 확인하고, 동시성을 테스트할 수 있는지에 초점을 맞추다 보니 통합 테스트 형태로 작성할 수밖에 없었습니다.
테스트의 어려움과 원인
- 동시성 시나리오 재현의 복잡성: 여러 스레드나 프로세스에서 동시에 조회수를 증가시키는 상황을 재현해야 했습니다.
- 실제 데이터 저장소 사용 필요성: 단위 테스트로는 Redis와 RDB 간의 데이터 일관성을 충분히 검증하기 어려웠습니다.
- 환경 설정의 복잡성: 통합 테스트를 위해 Redis와 RDB를 포함한 전체 애플리케이션 환경을 구축해야 했습니다.
해결 방법
통합 테스트를 통한 동시성 검증
ExecutorService와 CountDownLatch를 활용하여 다수의 스레드에서 동시에 조회수 증가 메서드를 호출하도록 했습니다.
@Test
@DisplayName("동시성 테스트 - PC, Mobile 히트 카운트 증가 및 저장")
void incrementHitCountConcurrentlyWithUpdateHitStorage() throws InterruptedException, ExecutionException {
Random random = new Random();
int loopCount = 100;
// 스레드 풀 생성
int numberOfThreads = 100;
ExecutorService executorService = Executors.newFixedThreadPool(numberOfThreads / 10);
// 전체 작업 수에 대한 CountDownLatch 설정
CountDownLatch latch = new CountDownLatch(loopCount * numberOfThreads);
// updateHitStorage 스레드 종료를 위한 플래그
AtomicBoolean isRunning = new AtomicBoolean(true);
// updateHitStorage를 실행하는 스레드 추가
ExecutorService updateExecutorService = Executors.newSingleThreadExecutor();
Future<?> updateFuture = updateExecutorService.submit(() -> {
try {
// 조회수가 몰리는 동안 주기적으로 updateHitStorage 실행
while (isRunning.get()) {
articleHitStorageService.updateHitStorage();
Thread.sleep(500); // 500ms마다 실행
}
// 마지막으로 남은 데이터 처리
articleHitStorageService.updateHitStorage();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
for (int z = 0; z < loopCount; z++) {
// Given
int randomNum = 10000000 + random.nextInt(90000000);
String articleId = String.valueOf(randomNum);
int incrementPerThread = 1;
// 조회수 증가 작업
for (int i = 0; i < numberOfThreads; i++) {
executorService.execute(() -> {
try {
articleHitRepository.incrementPcHitCount(articleId, incrementPerThread);
articleHitRepository.incrementMobileHitCount(articleId, incrementPerThread);
} finally {
latch.countDown();
}
});
}
}
// 모든 조회수 증가 작업 완료 대기
latch.await();
executorService.shutdown();
// 조회수 증가 작업이 모두 완료되었으므로 updateHitStorage 스레드 종료 플래그 설정
isRunning.set(false);
// updateHitStorage 스레드 종료 대기
updateExecutorService.shutdown();
updateFuture.get(); // 혹은 updateExecutorService.awaitTermination() 사용
// Then
// 최종적으로 Redis와 RDB에 데이터가 일관되게 저장되었는지 확인
List<ArticleHit> articleHitList = articleHitRepository.findAllBy();
log.info("articleHitList (Redis): {}", articleHitList);
List<ArticleHitStorage> articleHitStorageList = articleHitStorageRepository.findAll();
log.info("articleHitStorageList (RDB): {}", articleHitStorageList);
// Assertions를 통해 데이터 검증
// Redis에 남아 있는 데이터와 RDB에 저장된 데이터의 합이 기대한 값과 일치하는지 확인
int totalHitCount = articleHitStorageList.stream()
.mapToInt(ArticleHitStorage::getHitCount)
.sum();
int totalMobileHitCount = articleHitStorageList.stream()
.mapToInt(ArticleHitStorage::getMobileHitCount)
.sum();
int expectedTotalCount = loopCount * numberOfThreads;
Assertions.assertThat(totalHitCount).isEqualTo(expectedTotalCount);
Assertions.assertThat(totalMobileHitCount).isEqualTo(expectedTotalCount);
// Redis에 남아 있는 데이터가 없는지 확인 (모두 RDB로 이동되었으므로)
Assertions.assertThat(articleHitList).isEmpty();
}결론
Redis를 활용하여 조회수 시스템을 최적화하면서 발생한 동시성 이슈를 해결하기 위해 다양한 방법을 모색했습니다. Redis의 원자적 연산과 Lua 스크립트를 활용하여 동시성 문제를 효과적으로 해결할 수 있었습니다.
이번 경험을 통해 대용량 트래픽 환경에서 데이터 일관성을 유지하면서 성능을 최적화하는 방법에 대해 깊이 있게 이해하게 되었습니다. 앞으로도 Redis의 다양한 기능을 적극 활용하여 더욱 안정적이고 효율적인 시스템을 구축할 예정입니다.
'Framework > Spring Boot' 카테고리의 다른 글
| Spring Boot 기반 다수의 프로젝트를 하나의 Multi Module 프로젝트로 통합하기 (2) - 인증과 인가를 담당하는 Auth Api (1) | 2024.11.01 |
|---|---|
| Spring Boot 기반 다수의 프로젝트를 하나의 Multi Module 프로젝트로 통합하기 (1) - 프로젝트를 시작하며 (3) | 2024.10.30 |
| Spring Boot에서 발생하는 직렬화 오류 해결 가이드 (0) | 2024.10.08 |
| RabbitMQ 활용하기 (8) | 2024.09.30 |
| 스프링에서 TransactionManager에 대한 상세한 이해하기 (2) | 2024.09.24 |

댓글