
새로운 기술을 접할 때, 생소한 단어 때문에 학습하기 전부터 두려움을 느끼는 것은 개발자라면 한번쯤 가졌을 것이다. 나또한 지금 카프카 학습을 하면서 매우 당황스러울때가 많다. 때문에 Kafka Clustering과 Kafka Partitioning을 구현하기 전에, 각각의 용어에 대해 이해할겸 설명하는 과정부터 시작해보자.
1. 클러스터, 브로커, 토픽, 파티션
Apache Kafka의 주요 구성 요소인 주피터 클러스터(Zookeeper Cluster), 클러스터(Kkafka Cluster), 브로커(Broker), 토픽(Topic), 파티션(Partition)에 대해 아래와 같이 간략하게 정리해보았다.
주피터 클러스터 (Zookeeper Cluster)
역할
Kafka 클러스터의 메타데이터 관리, 브로커 간의 동기화, 클러스터 상태 유지.
필요성
Kafka 클러스터의 정확한 작동을 위해 메타데이터(토픽, 파티션 정보 등)를 저장하고 관리한다. 브로커 장애 및 네트워크 분할 시 클러스터 상태를 유지하며, 브로커들 간의 리더 선출 등을 관리한다.
클러스터 (Kafka Cluster)
역할
대규모 메시지 데이터의 분산 처리 및 저장.
필요성
Kafka 클러스터는 높은 처리량과 확장성을 제공하며, 대용량의 실시간 데이터 스트리밍 처리를 가능하게 한다. 클러스터 구성을 통해 단일 시스템의 부하와 한계를 극복하고, 데이터의 병렬 처리 및 분산 저장을 지원한다.
브로커 (Broker)
역할
Kafka 클러스터 내의 서버 노드로, 메시지 데이터의 수신, 저장, 전달 담당.
필요성
각 브로커는 독립적으로 작동하여 클라이언트의 요청(데이터의 발행 및 구독)을 처리한다. 브로커들은 데이터의 복제, 부하 분산 및 고가용성을 위해 협력한다.
토픽 (Topic)
역할
메시지 데이터를 카테고리화하는 논리적 채널.
필요성
토픽은 데이터를 구조화하는 방법을 제공한다. 예를 들어, 서로 다른 유형의 메시지(예: 로그, 주문, 이벤트 등)를 서로 다른 토픽에 저장하여 처리한다. 토픽을 통해 데이터의 효율적인 관리와 접근이 가능해진다.
파티션 (Partition)
역할
토픽 내에서 데이터를 나누어 저장하는 단위. 각 파티션은 순차적인 메시지 시퀀스를 유지.
필요성
파티션을 통해 데이터는 병렬로 처리되고, 브로커 간에 분산 저장된다. 이는 데이터 처리의 확장성을 제공하며, 특정 토픽의 데이터 처리량이 증가해도 시스템 전체의 성능을 유지할 수 있게 한다. 또한, 파티션별로 데이터 복제를 통해 데이터의 내구성과 가용성을 향상시킨다.
2. 다중 브로커 생성 및 클러스터 연결
이전에 도커 이미지를 사용하여 단일 브로커를 생성하여 클러스터에 연결하였었는데, 이번에는 주피터 클러스터 컨테이너를 생성하여 두 개의 브로커 컨테이너를 만들어 연결시켜보자.
클러스터 컨테이너 생성
아래 도커 명령어를 사용하여 Zookeeper Cluster 컨테이너를 생성 및 실행한다.
docker run -d --name zookeeper -p 2181:2181 zookeeper연결 전 고려 사항
대규모 트래픽이 발생하는 서비스의 경우, 여러 서버에 분산된 클러스터를 구축하는 것이 일반적이다. 이렇게 하면 단일 시스템의 부하를 분산시키고, 시스템의 장애나 다운타임이 전체 서비스에 미치는 영향을 줄일 수 있을 것이다. 또한, 데이터의 병렬 처리와 분산 저장을 보다 효과적으로 수행할 수 있을 것이다.
또한, 클러스터는 일반적으로 여러 브로커를 포함한다. 포스팅 처음에서 설명한 것과 같이 클러스터는 데이터의 병렬 처리와 분산 저장을 위해 여러 브로커를 포함하며 이를 통해 고가용성과 확장성을 달성하기 때문이다.
때문에 서버가 하나만 있는 나와 같은 환경에서 학습을 위해 하나의 클러스터에 두 개의 브로커를 구성해보는 것이다. 이 경우, 두 브로커가 동일한 물리적 서버의 리소스를 공유하기 때문에 고가용성이나 장애 복구 측면에서 이점이 많지 않음을 명확히 알고 있어야 한다.
소규모 서비스를 운영하는 회사의 경우에도 단일 서버에서 여러 브로커를 운영할 경우, 리소스 할당과 관리에 주의해야 한다. 각 브로커가 충분한 메모리와 CPU 자원을 할당받도록 구성해야 하며, 네트워크 대역폭 또한 적절히 관리할 필요가 있다.
첫 번째 카프카 브로커 생성 및 실행 및 클러스터 연결
아래 도커 명령어를 사용하여 위에서 생성된 클러스터와 새로 생성하는 kafka-1 이름의 브로커를 연결한다.
docker run -d --name kafka-1 -p 9092:9092 \
--env KAFKA_BROKER_ID=1 \
--env KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \
--env KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT \
--env KAFKA_LISTENERS=INTERNAL://kafka-1:9093,EXTERNAL://:9092 \
--env KAFKA_ADVERTISED_LISTENERS=INTERNAL://kafka-1:9093,EXTERNAL://<카프카 서버 IP>:9092 \
--env KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \
--env KAFKA_INTER_BROKER_LISTENER_NAME=INTERNAL \
--link zookeeper:zookeeper wurstmeister/kafka
이어서 아래 도커 명령어를 사용하여 클러스터와 새로 생성하는 kafka-2 이름의 브로커를 연결한다.
docker run -d --name kafka-2 -p 9093:9092 \
--env KAFKA_BROKER_ID=2 \
--env KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \
--env KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT \
--env KAFKA_LISTENERS=INTERNAL://kafka-2:9094,EXTERNAL://:9093 \
--env KAFKA_ADVERTISED_LISTENERS=INTERNAL://kafka-2:9094,EXTERNAL://<카프카 서버 IP>:9093 \
--env KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \
--env KAFKA_INTER_BROKER_LISTENER_NAME=INTERNAL \
--link zookeeper:zookeeper wurstmeister/kafka각 docker run 명령어에서 --link 플래그를 사용하여 컨테이너 간의 연결을 설정한다. 이는 Docker Compose의 depends_on 설정과 유사한 역할을 한다. 또한, KAFKA_ADVERTISED_LISTENERS에 지정된 외부 IP는 실제 사용 환경에 맞게 조정해야 한다.
3. 클러스터 관리 도구 설치
Kafdrop은 Apache Kafka 클러스터를 위한 웹 기반 UI 도구이다. 이 도구는 Kafka 클러스터의 상태를 시각적으로 모니터링하고 관리할 수 있도록 설계되었다. Kafdrop을 사용하면 Kafka의 토픽, 파티션, 메시지, 소비자 그룹 등을 쉽게 파악하고 검토할 수 있게 된다. 때문에 개발 및 테스트, 운영 모니터링 등에 사용된다.
KafDrop 설치 및 연동
아래의 명령어를 통해 kafdrop 이미지를 pull받아 실행시킬 수 있다. SERVER_SERVLET_CONTEXTPATH 환경변수를 설정하여 본인이 kafDrop 웹 인터페이스에 접근할 때 사용할 URI를 정의할 수 있다. 나는 단순하게 /kafdrop 이라고 설정했다.
docker run -d --name kafdrop -p 9000:9000 \
--env KAFKA_BROKERCONNECT=kafka-1:9092,kafka-2:9093 \
--env JVM_OPTS="-Xms32M -Xmx64M" \
--env SERVER_SERVLET_CONTEXTPATH="/kafdrop" \
--link kafka-1:kafka-1 \
--link kafka-2:kafka-2 \
obsidiandynamics/kafdrop
4. 클러스터링 확인
docker process가 잘 실행되었는지 확인해본다. 나의 경우 정상적으로 주피터 클러스터, 브로커 1, 브로커 2, kafdrop 컨테이너들이 작동하는것을 확인할 수 있었다.
docker ps -a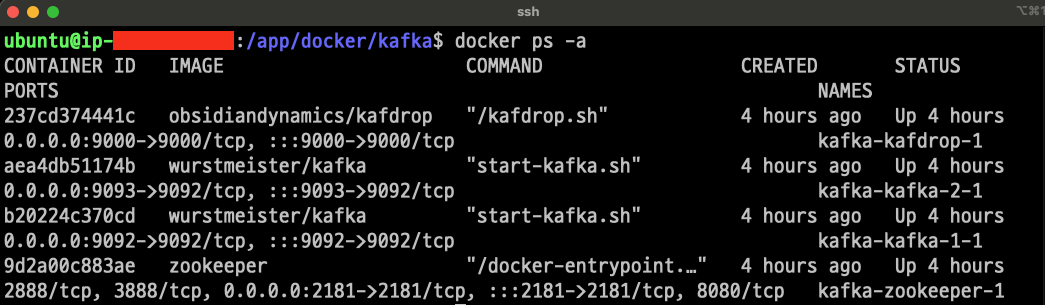
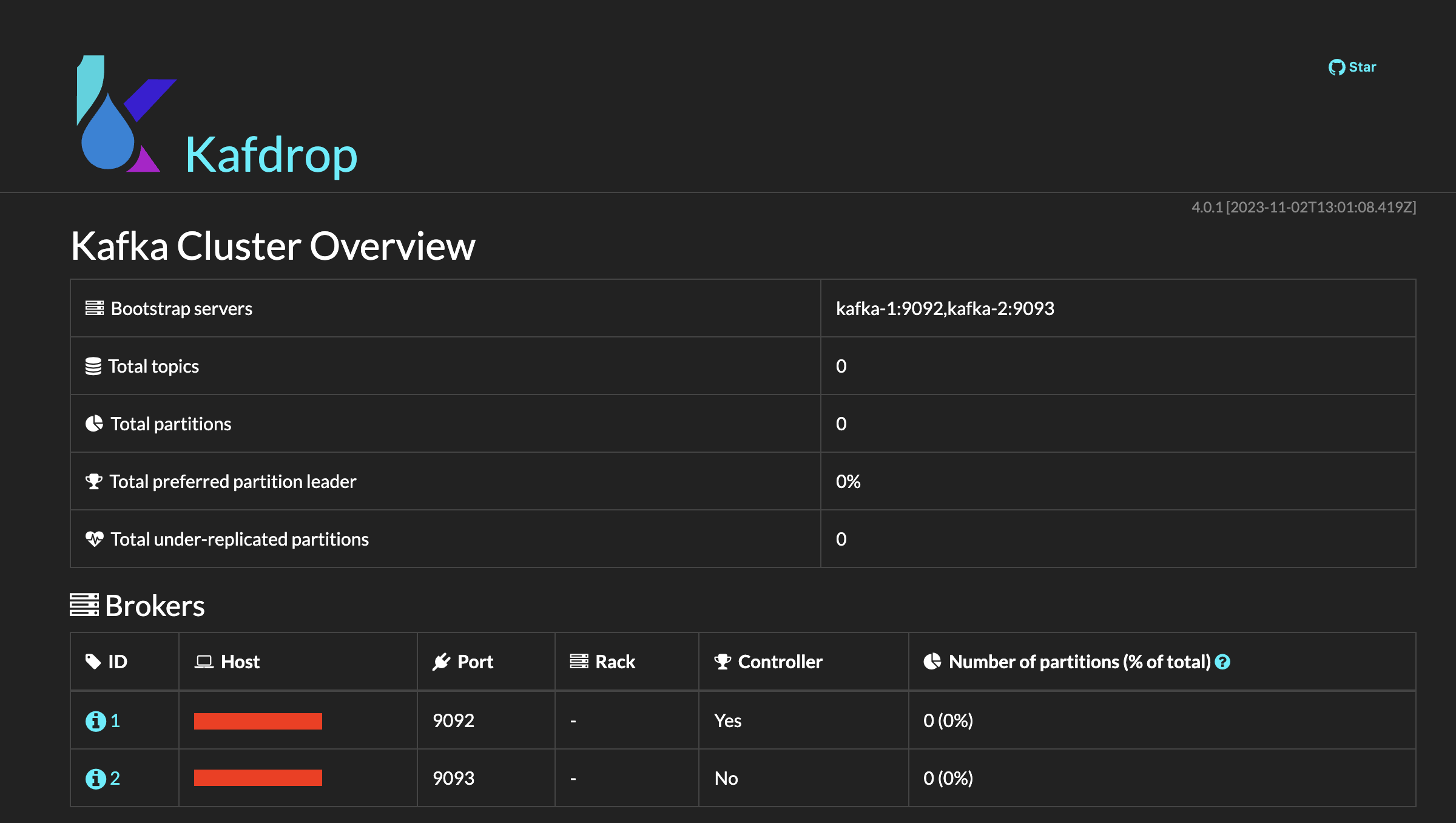
사용하는 서버에서 인바운드 규칙이 허용되어있다면 본인의 서버 ip 혹은 endpoint 주소 뒤에 :9000/kafdrop/ 로 접속하면 아래와 같이 정상적으로 연결 및 작동되고 있는 것을 확인할 수 있다.
나의 경우 AWS EC2 인스턴스의 인바운드 규칙에 9000(kafDrop), 9002(브로커1), 9003(브로커2) 3가지 포트를 허용해주었다.
5. 파티셔닝 (Partitioning)
파티셔닝(Partitioning)은 Kafka Topic 데이터를 물리적으로 분할하고 관리하는 방법을 지칭하는 개념이다. 파티션은 Kafka Topic의 데이터를 물리적으로 분할하는 단위로, 데이터의 병렬 처리 및 확장성을 제공하기 때문에 성능,확장성,내구성을 위한 핵심적인 전략이며, 토픽의 데이터 관리와 시스템 운영에 중요한 역할을 한다.
카프카 토픽 생성
Kafka에서 토픽과 파티션을 생성하는 방법은 몇 가지 있지만, 가장 일반적인 방법은 Kafka의 커맨드 라인 도구를 사용하는 것이다. 아래 명령어는 카프카 컨테이너 내에서 특정 토픽을 생성하는 명령이다. 이 명령은 토픽 이름과 더불어 파티션 및 복제본의 수를 설정할 수 있다.
docker exec -it kafka-1 kafka-topics.sh --create --topic mingyu --partitions 3 --replication-factor 2 --bootstrap-server localhost:9092--create: 토픽을 생성.
--topic: 생성할 토픽의 이름을 지정.
--partitions: 생성할 토픽의 파티션 수를 지정.
--replication-factor: 각 파티션의 복제본 수를 지정.
--bootstrap-server: Kafka 브로커의 주소를 지정.
특정 브로커에서 토픽을 생성해도 되는가?
위 명령어는 kafka-kafka-1-1 도커 컨테이너에 접속해서 토픽을 생성하는 것이다. 그렇다면, kafka-1 브로커에만 토픽이 생성되는거 아닌가? 라는 의문점이 생긴다. 하지만 실상은 그렇지 않다는 것을 명령어를 실행해보면 알 수 있다.
Kafka에서 토픽을 생성할 때, 토픽은 클러스터 전체에 걸쳐 생성되고 관리된다. 토픽 생성 명령을 특정 Kafka 브로커 컨테이너에서 실행하더라도, 해당 토픽은 Kafka 클러스터의 모든 브로커에 걸쳐 사용할 수 있다는 것이다. 이는 Kafka의 분산 시스템 아키텍처의 일부이다.
토픽 생성 시 --bootstrap-server 옵션으로 지정하는 Kafka 브로커 주소는 토픽을 생성하거나 관리하기 위해 연결할 브로커를 지정하는 것이다. 때문에 위의 토픽 생성 명령은 kafka-1 브로커에 연결하여 my-topic이라는 토픽을 생성하지만, 실제로 이 토픽은 클러스터의 모든 브로커에 걸쳐 생성되게 된다. 이후 이 토픽은 클러스터의 모든 브로커에서 사용할 수 있으며, 다른 브로커에서도 토픽의 데이터를 읽고 쓸 수 있다.
6. 파티셔닝 확인
명령어를 입력하여 실제로 토픽이 잘 생성되는지 확인해보자. 나의 경우 여러번 테스트 하면서 kafka-1 브로커를 가지고 있는 도커 컨테이너의 이름이 kafka-kafka-1-1 이 되었기 때문에 exec 옵션의 컨테이너명만 변경해주고 실행했다.

이제 KafDrop에 접속해서 두 개의 브로커에 3개의 파티션이 골고루 분배되었는지 확인해보자.
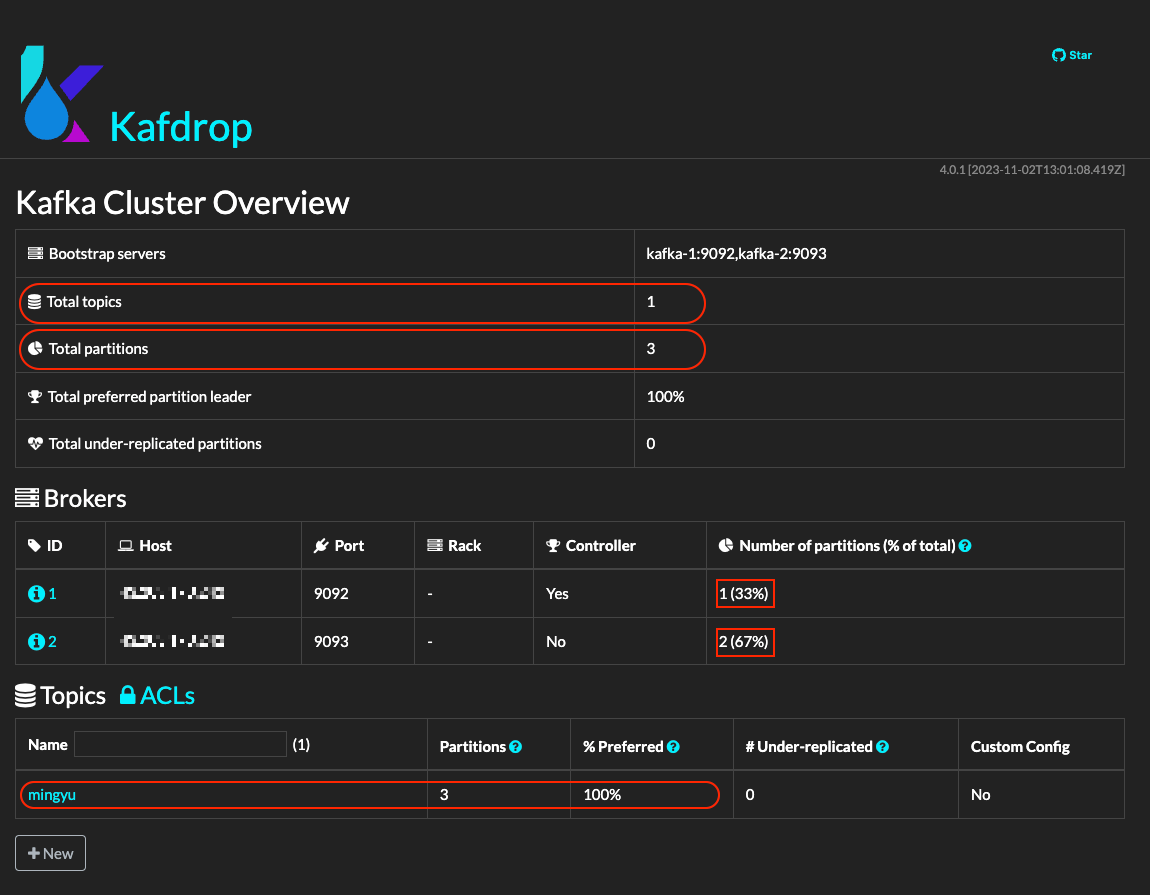
Kafka에서 토픽을 생성할 때, 파티션의 배분은 Kafka 클러스터의 브로커들 사이에서 이루어지며, 이 과정은 Kafka의 파티션 할당 알고리즘에 의해 처리된다.
파티션 할당 방식
균등 분배
Kafka는 가능한 한 모든 브로커에 파티션을 균등하게 분배하려고 한다. 이는 단일 브로커에 과도한 부하가 걸리는 것을 방지하기 위함이다.
리더 분배
각 파티션에는 리더가 있으며, 리더는 해당 파티션의 읽기 및 쓰기 작업을 관리한다. Kafka는 리더 파티션도 가능한 한 균등하게 브로커들 사이에 분배한다.
복제본 분산
파티션의 복제본은 원본 파티션과 다른 브로커에 위치한다. 이는 데이터의 내구성과 가용성을 보장한다.
예를 들어 클러스터에 3개의 브로커(kafka-1, kafka-2, kafka-3)가 있고, 3개의 파티션을 가진 토픽을 생성한다면, Kafka는 다음과 같이 파티션을 할당할 수 있다.
- 파티션 0: 리더는 kafka-1, 복제본은 kafka-2, kafka-3
- 파티션 1: 리더는 kafka-2, 복제본은 kafka-3, kafka-1
- 파티션 2: 리더는 kafka-3, 복제본은 kafka-1, kafka-2
번외
나는 학습을 위해서 (사실 돈이 없어서) 프리 티어를 가지고 구현을 했다. 하지만 이게 왠걸. ec2에는 도커 패키지만 설치했고, 작동하는 컨테이너는 꼴랑 4개 (zookeeper, kafdrop, kafka-1, kafka-2)인데도 불구하고, 아무것도 하지 않았는데 메모리 사용량이 한계점이다.
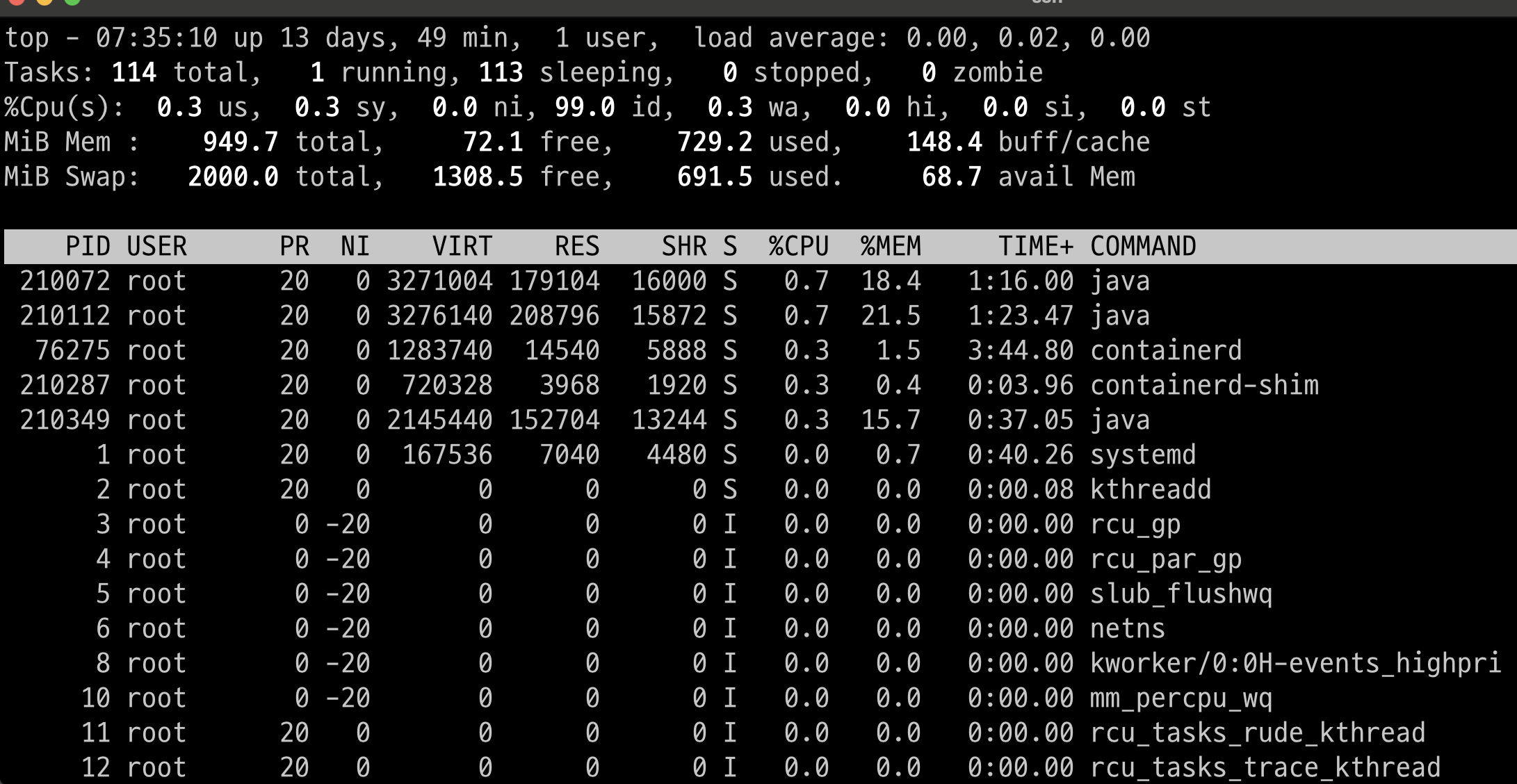
가동 프로세스중 상위 11개의 pid를 확인해보았다.
ps -eo pid,ppid,rss,size,pmem,pcpu,time --sort -rss | head -n 11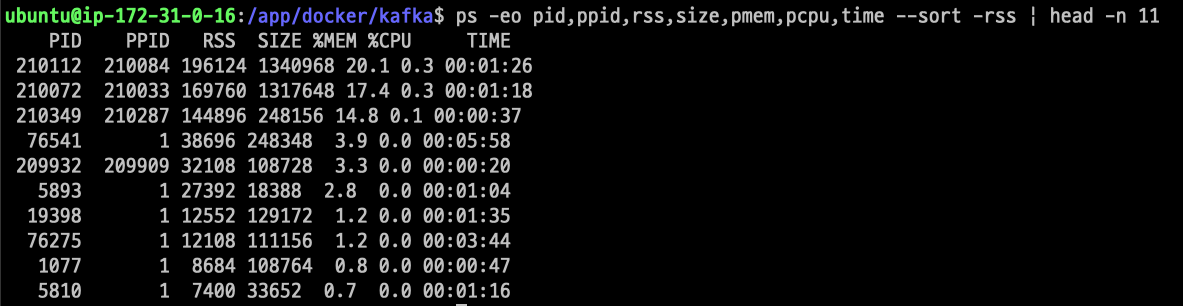
top 명령어로 확인해본 결과 zookeeper,kafka-1,kafka-2를 동작시키기 위한 java가 memory 사용량이 높은것을 확인했고, 자그마치 60%는 사용하는듯 했다. 토픽 생성 명령어 하나에도 3~5초 딜레이가 되는것이라면, AWS EC2 프리티어로 카프카에 대한 학습을 진행하는 것은 구축 단계까지만 하는것이 심상에 이로울 듯 하다.
그래서 찾아보았다. 카프카 클러스터 하드웨어 구성시 최소 사양은 메모리 4GB, 최소 CPU 2코어, 디스크 50GB (SSD 권장), 1Gbps의 이더넷 네트워크가 요구된다. 권장 요구 사양은 메모리 8GB, 8코어 이상의 CPU, 32GB 이상의 Ram, RAID 구성의 SSD, 10Gbps의 이더넷 네트워크가 요구된다. 서버 구성시 참고하여 구성하자.
Kafka Hardware Requirements
Kafka Hardware Requirements
medium.com
'Infrastructure > Kafka' 카테고리의 다른 글
| [Kafka 서버 구축] AWS EC2 인스턴스에 Docker를 사용하여 Kafka와 Zookeeper를 연동해서 Kafka 서버 구축하기 (1) | 2024.02.14 |
|---|---|
| MacOs에 PHP-RdKafka 설정 및 셋팅하기 (0) | 2022.05.16 |
| Apache Kafka란? - 아파치 카프카에 대한 학습 (0) | 2022.04.26 |

댓글